 DIEN
DIEN
# DIEN
# 1. DIEN提出的动机
在推荐场景,用户无需输入搜索关键词来表达意图,这种情况下捕捉用户兴趣并考虑兴趣的动态变化将是提升模型效果的关键。以Wide&Deep为代表的深度模型更多的是考虑不同field特征之间的相互作用,未关注用户兴趣。
DIN模型考虑了用户兴趣,并且强调用户兴趣是多样的,该模型使用注意力机制来捕捉和target item的相关的兴趣,这样以来用户的兴趣就会随着目标商品自适应的改变。但是大多该类模型包括DIN在内,直接将用户的行为当做用户的兴趣(因为DIN模型只是在行为序列上做了简单的特征处理),但是用户潜在兴趣一般很难直接通过用户的行为直接表示,大多模型都没有挖掘用户行为背后真实的兴趣,捕捉用户兴趣的动态变化对用户兴趣的表示非常重要。DIEN相比于之前的模型,即对用户的兴趣进行建模,又对建模出来的用户兴趣继续建模得到用户的兴趣变化过程。
# 2. DIEN模型原理
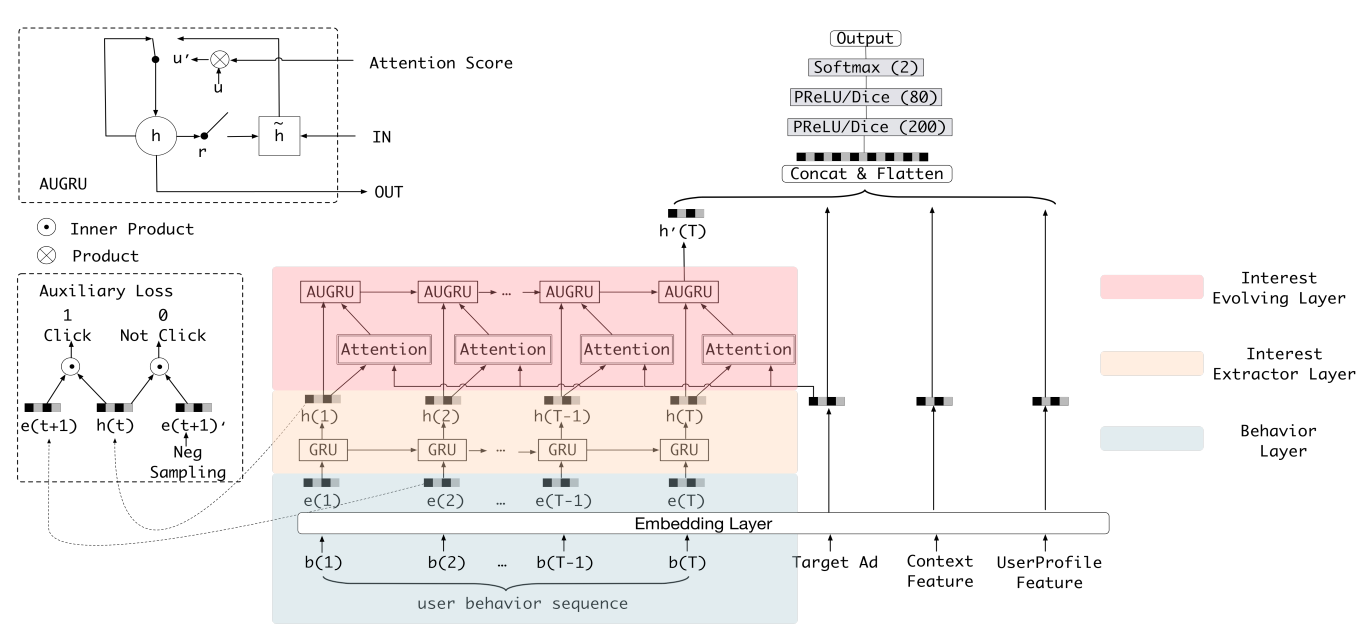
模型的输入可以分成两大部分,一部分是用户的行为序列(这部分会通过兴趣提取层及兴趣演化层转换成与用户当前兴趣相关的embedding),另一部分就是除了用户行为以外的其他所有特征,如Target id, Coontext Feature, UserProfile Feature,这些特征都转化成embedding的类型然后concat在一起(形成一个大的embedding)作为非行为相关的特征(这里可能也会存在一些非id类特征,应该可以直接进行concat)。最后DNN输入的部分由行为序列embedding和非行为特征embedding(多个特征concat到一起之后形成的一个大的向量)组成,将两者concat之后输入到DNN中。
所以DIEN模型的重点就是如何将用户的行为序列转换成与用户兴趣相关的向量,在DIN中是直接通过与target item计算序列中每个元素的注意力分数,然后加权求和得到最终的兴趣表示向量。在DIEN中使用了两层结构来建模用户兴趣相关的向量。
# 2.1 Interest Exterator Layer
兴趣抽取层的输入原本是一个id序列(按照点击时间的先后顺序形成的一个序列),通过Embedding层将其转化成一个embedding序列。然后使用GRU模块对兴趣进行抽取,GRU的输入是embedding层之后得到的embedding序列。对于GRU模块不是很了解的可以看一下动手学深度学习中GRU相关的内容 (opens new window)
作者并没有直接完全使用原始的GRU来提取用户的兴趣,而是引入了一个辅助函数来指导用户兴趣的提取。作者认为如果直接使用GRU提取用户的兴趣,只能得到用户行为之间的依赖关系,不能有效的表示用户的兴趣。因为是用户的兴趣导致了用户的点击,用户的最后一次点击与用户点击之前的兴趣相关性就很强,但是直接使用行为序列训练GRU的话,只有用户最后一次点击的物品(也就是label,在这里可以认为是Target Ad), 那么最多就是能够捕捉到用户最后一次点击时的兴趣,而最后一次的兴趣又和前面点击过的物品在兴趣上是相关的,而前面点击的物品中并没有target item进行监督。所以作者提出的辅助损失就是为了让行为序列中的每一个时刻都有一个target item进行监督训练,也就是使用下一个行为来监督兴趣状态的学习
辅助损失
首先需要明确的就是辅助损失是计算哪两个量的损失。计算的是用户每个时刻的兴趣表示(GRU每个时刻输出的隐藏状态形成的序列)与用户当前时刻实际点击的物品表示(输入的embedding序列)之间的损失,相当于是行为序列中的第t+1个物品与用户第t时刻的兴趣表示之间的损失**(为什么这里用户第t时刻的兴趣与第t+1时刻的真实点击做损失呢?我的理解是,只有知道了用户第t+1真实点击的商品,才能更好的确定用户第t时刻的兴趣)。**
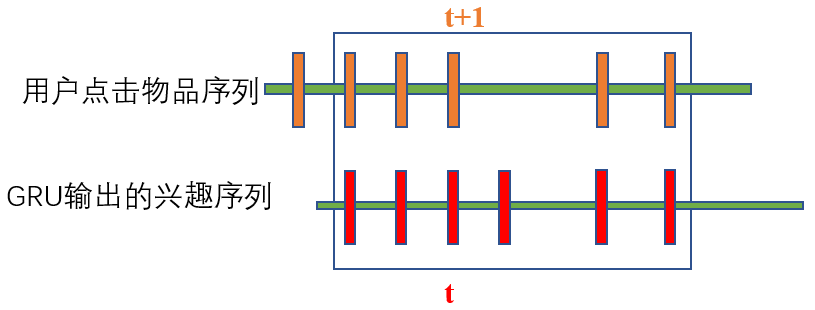
当然,如果只计算用户点击物品与其点击前一次的兴趣之间的损失,只能认为是正样本之间的损失,那么用户第t时刻的兴趣其实还有很多其他的未点击的商品,这些未点击的商品就是负样本,负样本一般通过从用户点击序列中采样得到,这样一来辅助损失中就包含了用户某个时刻下的兴趣及与该时刻兴趣相关的正负物品。所以最终的损失函数表示如下。
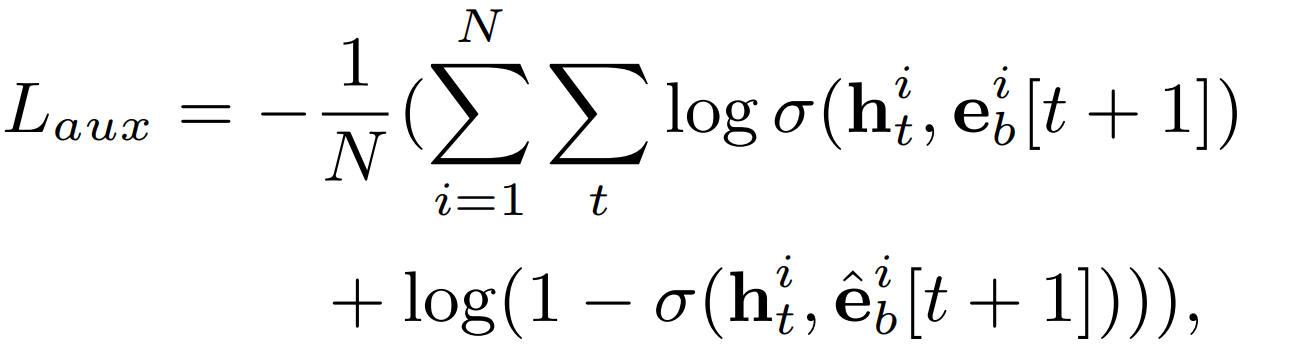
其中$h_t^i$表示的是用户$i$第$t$时刻的隐藏状态,可以表示用户第$t$时刻的兴趣向量,$e_b^i,\hat{e_b^i}$分别表示的是正负样本,$e_b^i[t+1]$表示的是用户$i$第$t+1$时刻点击的物品向量。
辅助损失会加到最终的目标损失(ctr损失)中一起进行优化,并且通过$\alpha$参数来平衡点击率和兴趣的关系 $$ L = L_{target} + \alpha L_{aux} $$
引入辅助函数的函数有:
辅助loss可以帮助GRU的隐状态更好地表示用户兴趣。
RNN在长序列建模场景下梯度传播可能并不能很好的影响到序列开始部分,如果在序列的每个部分都引入一个辅助的监督信号,则可一定程度降低优化难度。
辅助loss可以给embedding层的学习带来更多语义信息,学习到item对应的更好的embedding。
# 2.2 Interest Evolving Layer
将用户的行为序列通过GRU+辅助损失建模之后,对用户行为序列中的兴趣进行了提取并表达成了向量的形式(GRU每个时刻输出的隐藏状态)。而用户的兴趣会因为外部环境或内部认知随着时间变化,特点如下:
兴趣是多样化的,可能发生漂移。兴趣漂移对行为的影响是用户可能在一段时间内对各种书籍感兴趣,而在另一段时间却需要衣服
虽然兴趣可能会相互影响,但是每一种兴趣都有自己的发展过程,例如书和衣服的发展过程几乎是独立的。而我们只关注与target item相关的演进过程。
由于用户的兴趣是多样的,但是用户的每一种兴趣都有自己的发展过程,即使兴趣发生漂移我们可以只考虑用户与target item(广告或者商品)相关的兴趣演化过程,这样就不用考虑用户多样化的兴趣的问题了,而如何只获取与target item相关的信息,作者使用了与DIN模型中提取与target item相同的方法,来计算用户历史兴趣与target item之间的相似度,即这里也使用了DIN中介绍的局部激活单元(就是下图中的Attention模块)。
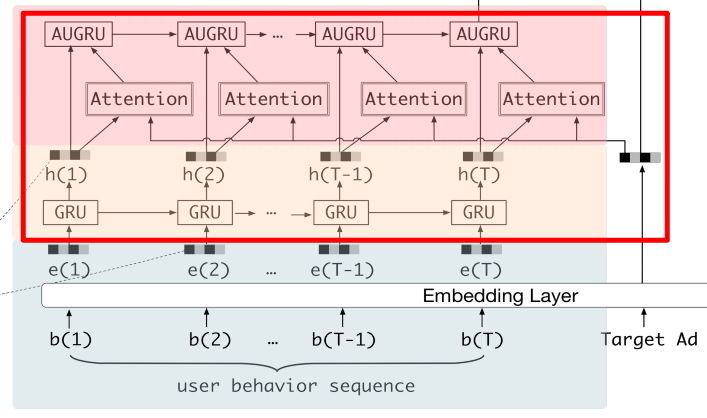
当得到了用户历史兴趣序列及兴趣序列与target item之间的相关性(注意力分数)之后,就需要再次对注意力序列进行建模得到用户注意力的演化过程,进一步表示用户最终的兴趣向量。此时的序列数据等同于有了一个序列及序列中每个向量的注意力权重,下面就是考虑如何使用这个注意力权重来一起优化序列建模的结果了。作者提出了三种注意力结合的GRU模型快:
AIGRU: 将注意力分数直接与输入的序列进行相乘,也就是权重越大的向量对应的值也越大, 其中$i_t^{'}, h_t, a_t$分别表示用户$i$在兴趣演化过程使用的GRU的第t时刻的输入,$h_t$表示的是兴趣抽取层第t时刻的输出,$a_t$表示的是$h_t$的注意力分数,这种方式的弊端是即使是零输入也会改变GRU的隐藏状态,所以相对较少的兴趣值也会影响兴趣的学习进化(根据GRU门的更新公式就可以知道,下一个隐藏状态的计算会用到上一个隐藏状态的信息,所以即使当前输入为0,最终隐藏状态也不会直接等于0,所以即使兴趣较少,也会影响到最终兴趣的演化)。 $$ i_t^{'} = h_t * a_t $$
AGRU: 将注意力分数直接作为GRU模块中,更新门的值,则重置门对应的值表示为$1-a_t$, 所以最终隐藏状态的更新公式表示为:其中$\hat{h_t^{'}}$表示的是候选隐藏状态。但是这种方式的弊端是弱化了兴趣之间的相关性,因为最终兴趣的更新前后是没关系的,只取决于输入的注意力分数 $$ h_t^{'} = (1-a_t)h_{t-1}^{'} + a_t * \tilde{h_t^{'}} $$
AUGRU: 将注意力分数作为更新门的权重,这样既兼顾了注意力分数很低时的状态更新值,也利用了兴趣之间的相关性,最终的表达式如下: $$ \begin{align} & \tilde{u_t^{'}} = a_t * u_t \ & h_t^{'} = (1-\tilde{u_t^{'}})h_{t-1}^{'} + \tilde{u_t^{'}} * \tilde{h_t^{'}} \end{align} $$
建模兴趣演化过程的好处:
追踪用户的interest可以使我们学习final interest的表达时包含更多的历史信息
可以根据interest的变化趋势更好地进行CTR预测
# 3. 代码实现
下面我们看下DIN的代码复现,这里主要是给大家说一下这个模型的设计逻辑,参考了deepctr的函数API的编程风格, 具体的代码以及示例大家可以去参考后面的GitHub,里面已经给出了详细的注释, 这里主要分析模型的逻辑这块。关于函数API的编程式风格,我们还给出了一份文档, 大家可以先看这个,再看后面的代码部分,会更加舒服些。下面开始:
这里主要和大家说一下DIN模型的总体运行逻辑,这样可以让大家从宏观的层面去把握模型的编写过程。该模型所使用的数据集是movielens数据集, 具体介绍可以参考后面的GitHub。 因为上面反复强调了DIN的应用场景,需要基于用户的历史行为数据, 所以在这个数据集中会有用户过去对电影评分的一系列行为。这在之前的数据集中往往是看不到的。 大家可以导入数据之后自行查看这种行为特征(hist_behavior)。另外还有一点需要说明的是这种历史行为是序列性质的特征, 并且不同的用户这种历史行为特征长度会不一样, 但是我们的神经网络是要求序列等长的,所以这种情况我们一般会按照最长的序列进行padding的操作(不够长的填0), 而到具体层上进行运算的时候,会用mask掩码的方式标记出这些填充的位置,好保证计算的准确性。 在我们给出的代码中,大家会在AttentionPoolingLayer层的前向传播中看到这种操作。下面开始说编写逻辑:
首先, DIN模型的输入特征大致上分为了三类: Dense(连续型), Sparse(离散型), VarlenSparse(变长离散型),也就是指的上面的历史行为数据。而不同的类型特征也就决定了后面处理的方式会不同:
- Dense型特征:由于是数值型了,这里为每个这样的特征建立Input层接收这种输入, 然后拼接起来先放着,等离散的那边处理好之后,和离散的拼接起来进DNN
- Sparse型特征,为离散型特征建立Input层接收输入,然后需要先通过embedding层转成低维稠密向量,然后拼接起来放着,等变长离散那边处理好之后, 一块拼起来进DNN, 但是这里面要注意有个特征的embedding向量还得拿出来用,就是候选商品的embedding向量,这个还得和后面的计算相关性,对历史行为序列加权。
- VarlenSparse型特征:这个一般指的用户的历史行为特征,变长数据, 首先会进行padding操作成等长, 然后建立Input层接收输入,然后通过embedding层得到各自历史行为的embedding向量, 拿着这些向量与上面的候选商品embedding向量进入AttentionPoolingLayer去对这些历史行为特征加权合并,最后得到输出。
通过上面的三种处理, 就得到了处理好的连续特征,离散特征和变长离散特征, 接下来把这三种特征拼接,进DNN网络,得到最后的输出结果即可。所以有了这个解释, 就可以放DIN模型的代码全貌了,大家可以感受下我上面解释的:
def DIEN(feature_columns, behavior_feature_list, behavior_seq_feature_list, neg_seq_feature_list, use_neg_sample=False, alpha=1.0):
# 构建输入层
input_layer_dict = build_input_layers(feature_columns)
# 将Input层转化为列表的形式作为model的输入
input_layers = list(input_layer_dict.values()) # 各个输入层
user_behavior_length = input_layer_dict["hist_len"]
# 筛选出特征中的sparse_fea, dense_fea, varlen_fea
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), feature_columns)) if feature_columns else []
varlen_sparse_feature_columns = list(filter(lambda x: isinstance(x, VarLenSparseFeat), feature_columns)) if feature_columns else []
# 获取dense
dnn_dense_input = []
for fc in dense_feature_columns:
dnn_dense_input.append(input_layer_dict[fc.name])
# 将所有的dense特征拼接
dnn_dense_input = concat_input_list(dnn_dense_input)
# 构建embedding字典
embedding_layer_dict = build_embedding_layers(feature_columns, input_layer_dict)
# 因为这里最终需要将embedding拼接后直接输入到全连接层(Dense)中, 所以需要Flatten
dnn_sparse_embed_input = concat_embedding_list(sparse_feature_columns, input_layer_dict, embedding_layer_dict, flatten=True)
# 将所有sparse特征的embedding进行拼接
dnn_sparse_input = concat_input_list(dnn_sparse_embed_input)
# 获取当前的行为特征(movie)的embedding,这里有可能有多个行为产生了行为序列,所以需要使用列表将其放在一起
query_embed_list = embedding_lookup(behavior_feature_list, input_layer_dict, embedding_layer_dict)
# 获取行为序列(movie_id序列, hist_movie_id) 对应的embedding,这里有可能有多个行为产生了行为序列,所以需要使用列表将其放在一起
keys_embed_list = embedding_lookup(behavior_seq_feature_list, input_layer_dict, embedding_layer_dict)
# 把q,k的embedding拼在一块
query_emb, keys_emb = concat_input_list(query_embed_list), concat_input_list(keys_embed_list)
# 采样的负行为
neg_uiseq_embed_list = embedding_lookup(neg_seq_feature_list, input_layer_dict, embedding_layer_dict)
neg_concat_behavior = concat_input_list(neg_uiseq_embed_list)
# 兴趣进化层的计算过程
dnn_seq_input, aux_loss = interest_evolution(keys_emb, query_emb, user_behavior_length, neg_concat_behavior, gru_type="AUGRU")
# 后面的全连接层
deep_input_embed = Concatenate()([dnn_dense_input, dnn_sparse_input, dnn_seq_input])
# 获取最终dnn的logits
dnn_logits = get_dnn_logits(deep_input_embed, activation='prelu')
model = Model(input_layers, dnn_logits)
# 加兴趣提取层的损失 这个比例可调
if use_neg_sample:
model.add_loss(alpha * aux_loss)
# 所有变量需要初始化
tf.compat.v1.keras.backend.get_session().run(tf.compat.v1.global_variables_initializer())
return model
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播。(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中(看不清的话可以自己用代码生成之后使用其他的软件打开看)。

# 4. 思考
- 对于知乎上大佬们对DIEN的探讨,你有什么看法呢?也评Deep Interest Evolution Network (opens new window)